Scene representation is a crucial design choice in robotic manipulation systems. An ideal representation is expected to be 3D, dynamic, and semantic to meet the demands of diverse manipulation tasks. However, previous works often lack all three properties simultaneously. In this work, we introduce D3Fields — dynamic 3D descriptor fields. These fields are implicit 3D representations that take in 3D points and output semantic features and instance masks. They can also capture the dynamics of the underlying 3D environments. Specifically, we project arbitrary 3D points in the workspace onto multi-view 2D visual observations and interpolate features derived from visual foundational models. The resulting fused descriptor fields allow for flexible goal specifications using 2D images with varied contexts, styles, and instances. To evaluate the effectiveness of these descriptor fields, we apply our representation to rearrangement tasks in a zero-shot manner. Through extensive evaluation in real worlds and simulations, we demonstrate that D3Fields are effective for zero-shot generalizable rearrangement tasks. We also compare D3Fields with state-of-the-art implicit 3D representations and show significant improvements in effectiveness and efficiency.
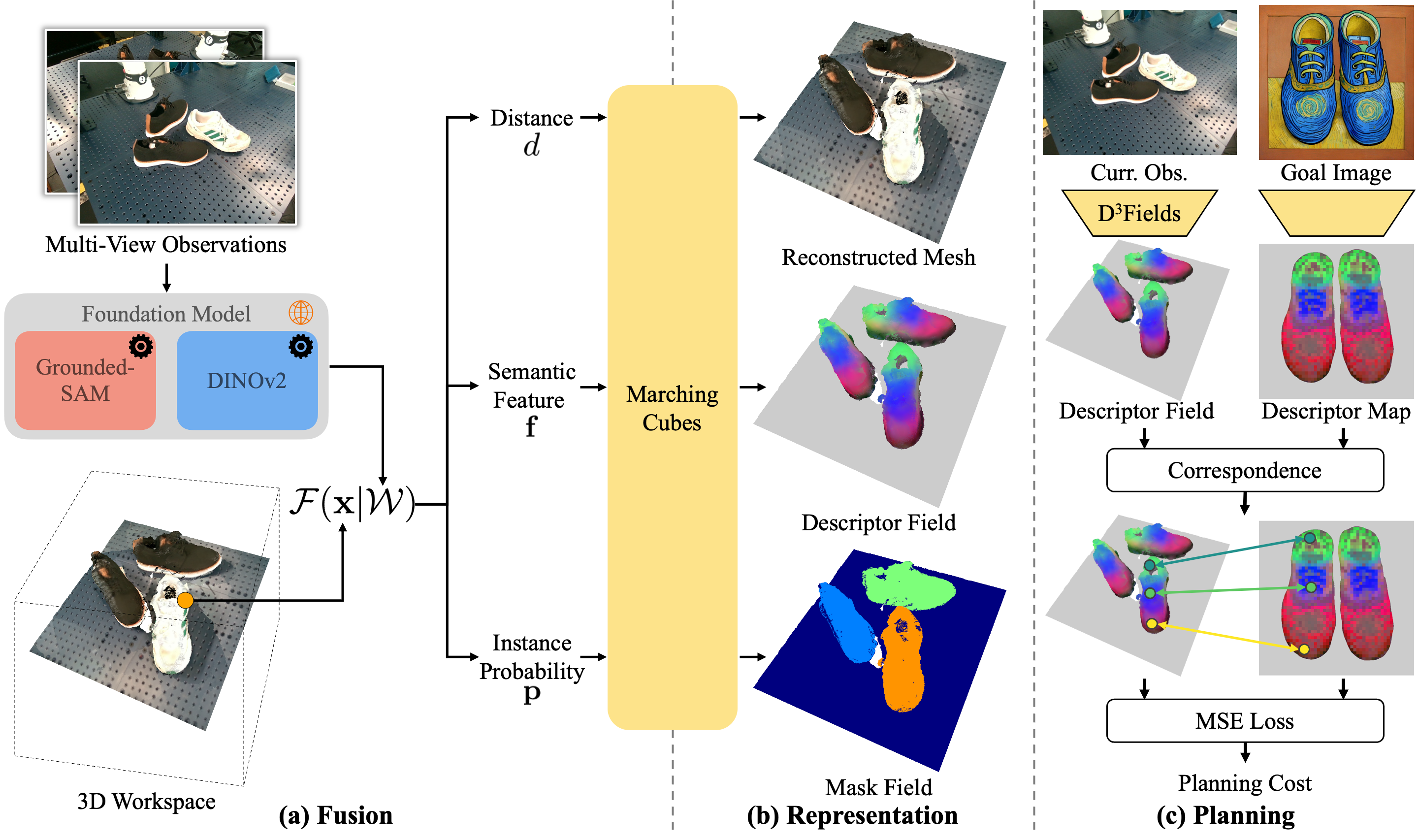
Overview of the proposed framework. (a) The fusion process fuses RGBD observations from multiple views. Each view is processed by foundation models to obtain the feature volume \(\mathcal{W}\). Arbitrary 3D points are processed through projection and interpolation. (b) After fusing information from multiple views, we obtain an implicit distance function to reconstruct the mesh form. We also have instance masks and semantic features for evaluated 3D points, as shown by the mask field and descriptor field in the top right subfigure. (c) Given a 2D goal image, we use foundation models to extract the descriptor map. Then we correspond 3D features to 2D features and define the planning cost based on the correspondence.
Mask Field
Descriptor Field
3D Tracking Visualization (Projected to Image Space)
3D Tracking Trace Visualization
@inproceedings{wang2024d3fields,
title={D$^3$Fields: Dynamic 3D Descriptor Fields for Zero-Shot Generalizable Rearrangement},
author={Wang, Yixuan and Zhang, Mingtong and Li, Zhuoran and Kelestemur, Tarik and Driggs-Campbell, Katherine and Wu, Jiajun and Fei-Fei, Li and Li, Yunzhu},
booktitle={8th Annual Conference on Robot Learning},
year={2024}
}